LLM-Übersetzung von internen Dokumenten
Die Ausgangslage
So viele Entwicklungsagenturen arbeiten seit Jahren an der technologischen Spitze der Fortschrittswelle. Und das bedeutet aktuell, KI-Integrationen für unterschiedlichste Anwendungsfälle zu verwirklichen. Und dennoch schöpfen die meisten Agenturen, wenn es um die Bereitstellung von Übersetzungen für ihre Kunden geht, bei Weitem nicht das mögliche Potenzial aus.
Diese Lücke liegt nicht daran, dass Agenturen technisch nicht in der Lage wären, entsprechende Lösungen umzusetzen. Nein, ihnen fehlt einfach die erforderliche sprachtechnologische Kompetenz und das Wissen, welche Informationen ein LLM eigentlich benötigt, um einen möglichst hochwertigen Output zu liefern, und wie die Kombination von traditionellen Sprachtechnologien mit LLM-Integration zu einem Quantensprung in der Qualität des Output führen kann.
Regelmäßig hören wir, dass Agenturen Machine Translation-Dienste wie DeepL oder auch ein LLM per API in ihre Systeme integriert haben, um unternehmensinterne Texte wie Lastenhefte oder Ersatzteillisten zu übersetzen. Und in vielen Fällen landen diese Übersetzungen ungeprüft im System und werden lückenhaft von den Landesvertretungen korrigiert, wenn eine Fehlübersetzung entdeckt wird. Diese Vorgehensweise führt nicht nur zu qualitativ minderwertigen Ergebnissen, sie verursacht teils erhebliche versteckte Kosten und birgt Gefahren durch unentdeckte Fehlübersetzungen. Dabei ginge es inzwischen erheblich besser:
TERMINOLOGIE
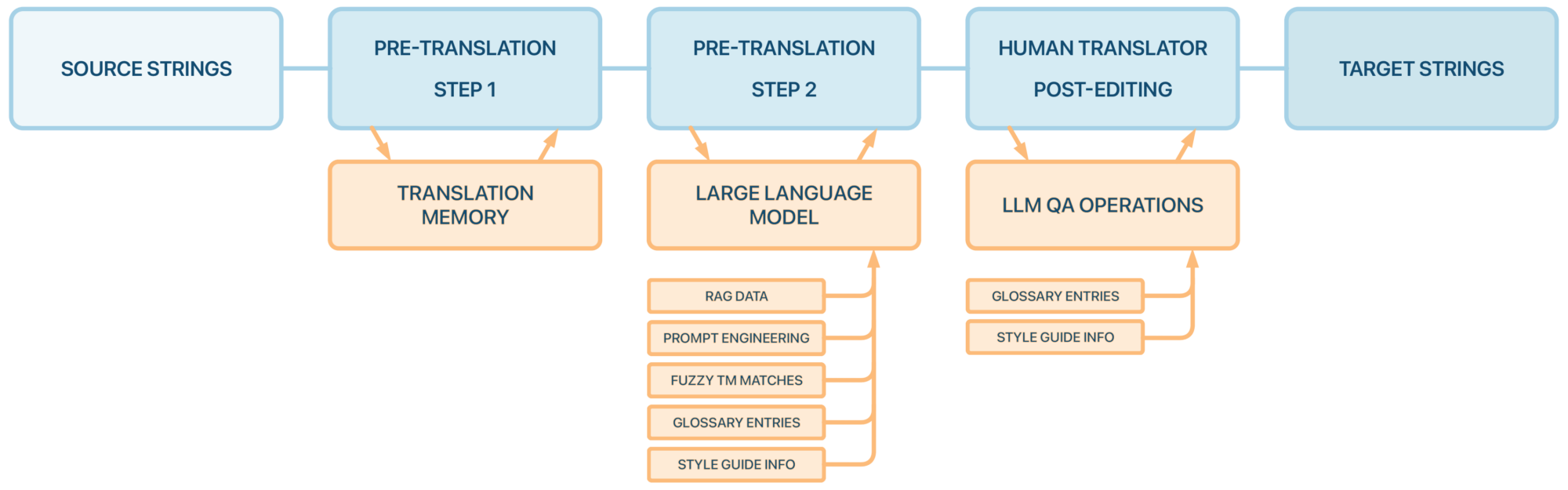
Der erste und wichtigste Schritt ist die Einbindung von fachspezifischer Terminologie in den KI/MT-Workflow. Speziell Dokumente für den internen Gebrauch, wie Lastenhefte, Spezifikationen, Teilelisten, usw., sind stark terminologielastig. Somit hängt der Erfolg (bei internen Texten überwiegend die Verständlichkeit von Texten) einer maschinellen Übersetzung überwiegend an der korrekten Wiedergabe der Fachtermini. Schließlich möchte ein Lieferant für landwirtschaftliche Maschinen, dass die Schneidmesser seiner Ballenpresse eben nicht als “Knives”, sondern korrekt als “Blades”, und die Presskammer der Ballenpresse nicht als “Press Chamber”, sondern als “Bale Chamber” übersetzt wird.
Diese mehrsprachige Terminologie-Datenbank muss natürlich (sofern noch nicht geschehen) erst einmal erstellt, und dann auch zeitnah gepflegt werden. Arbeit, die viele Unternehmen scheuen, weil niemand da ist, der die sprachliche und technische Kompetenz vereint. Denn diese Datenbank muss natürlich noch an der richtigen Stelle und mit den richtigen Anweisungen an die KI/MT übergeben werden, damit die darin enthaltenen Termini auch genutzt werden können.
DeepL API bietet eine rudimentäre Glossarfunktion, die jedoch einige Tücken birgt. So muss dort jedes Glossar pro Sprachenpaar separat verwaltet und gepflegt werden, was zu erheblichem Mehraufwand führt, und bei einer Vielzahl von Glossaren ganz schnell unübersichtlich wird.
Zudem ist die Erkennung von Komposita bei DeepL – naja, sagen wir mal euphemistisch – optimierungswürdig. Um bei einem der obigen Beispiele zu bleiben, ist es bei DeepL leider nicht garantiert, dass aus der “Bale Chamber” auch wirklich die “Presskammer” wird, wenn sowohl “Bale” als “Ballen”, als auch “Bale Chamber” als “Presskammer” im Glossar stehen.
KONTEXT
Wer nicht DeepL, sondern ein LLM zur maschinellen Vorübersetzung nutzt, hat die Möglichkeit, durch Prompts den Output des LLM zu steuern. Allgemeingültige Prompts zum vorliegenden Fachbereich, dem Einsatzzweck des zu generierenden Textes, der zu verwendenden sprachlichen Stilebene und Komplexität unterstützen das Shaping des Outputs zur gewünschten Textqualität.
Doch das Prompting allein ist ja nur die Spitze des Eisbergs. Mithilfe von RAG in KI-Agenten kann das LLM sämtliche Texte und Übersetzungen aus dem Bestand, ja sogar vorhandene Screenshots und Abbildungen, zur Kontextbestimmung nutzen, um möglichst präzise Übersetzungen anzufertigen. Die implementierte Lösung muss diese Funktionalität natürlich unterstützen. Eine eigene Programmierung solch einer Lösung kann sehr aufwands- und kostenintensiv sein, sodass die Kosten-Nutzen-Analyse dafür meist negativ ausfällt. Zum Glück gibt es bereits vorhandene Lösungen auf dem Markt, die ganz leicht in bestehende Workflows integriert werden können.
STILVORGABEN
Die beiden erstgenannten Punkte steigern die Output-Qualität bei stark stichpunktlastigen Texten schon enorm, doch sobald es an formulierte Texte geht, hängt der Erfolg der maschinellen Übersetzung ebenso an der Vorgabe von sprachlichen Konventionen. Wie werden Überschriften einheitlich formuliert? Wie sollen Anweisungen strukturiert sein? Wie formatiere ich Zahlen und Daten? Und wie sollen Komposita mit mehr oder weniger als drei Substantiven oder auch mit Markennamen gebildet werden? All diese Vorgaben werden bei der konventionellen Übersetzung mit professionellen Übersetzern in einem sprachlichen Style-Guide zusammengefasst (manche Unternehmen haben Style Guides, die bis zu 200 Seiten pro Sprache umfassen). Dieser Style Guide muss nun an die KI angepasst und übergeben werden, damit Fehler schon im Vorfeld ausgeschlossen oder zumindest minimiert werden können.
Solche Stilvorgaben sind stark sprachenabhängig, müssen also für jede Sprache separat verfasst, verwaltet und an die KI/MT übergeben werden. Für diese Aufgabe ist zum einen allgemeine linguistische Kompetenz, zum anderen die absolute Kenntnis der entsprechenden Sprache erforderlich. Diese Kompetenz muss in einem Unternehmen erstmal vorhanden sein oder akquiriert werden – ein nicht unerhebliches Unterfangen. Doch es geht auch anders. Lest gern weiter und erfahrt zum Schluss, welche einfachen Lösungen es gibt.
ÜBERSETZUNGSSPEICHER
Man muss nicht immer gleich den gesamten Text durch das LLM prügeln. Tatsächlich sollte man das sogar nicht tun, wenn man eh schon einen großen Korpus an zuvor übersetzten Texten hat. Mit dem Einsatz von konventionellen Übersetzungsspeichern werden identische bereits übersetzte Textsegmente direkt aus dem Übersetzungsspeicher übersetzt. Das hat den unglaublichen Vorteil der Gewissheit, dass diese Übersetzung korrekt ist. Schließlich kommt sie aus einer Datenbank an Übersetzungen, die geprüft und bestätigt wurden.
Doch die Möglichkeiten enden hier noch nicht. Denn auch wenn ähnliche, aber nicht identische Textsegmente bereits im Speicher vorhanden sind, können diese an das LLM übergeben werden mit der Ansage, diese unter Beibehaltung von Struktur und Stil minimal anzupassen. So stellt ihr sicher, dass die KI keine wilden Experimente mit Texten vollführt, die eigentlich nur mit minimalen Anpassungen aus dem Übersetzungsspeicher übernommen werden können.
DIE UMSETZUNG
Aber wie genau setzt man diese Praktiken nun in die Wirklichkeit um? Wie wir nun festgestellt haben, ist sprachliche Korrektheit komplexer als gedacht, und beinhaltet mehr, als nur Texte per API-Call an das LLM zu senden. Solch eine Lösung In-House zu fertigen, ist in fast allen Fällen völlig überzogen und kaum realisierbar. Aber dafür gibt es zum Glück bereits einige Anbieter von fertigen webbasierten Lösungen, wie zum Beispiel Crowdin.